Speaker Identification in MediaScribe
Speaker Identification in MediaScribe
This MediaScribe feature allows you to tag known members of your community in past or uploaded recordings. These speakers can be attached to your Preset and are used to give speakers named labels during live meetings. This speaker data will also be saved to your recordings for more readable transcripts.
Identifying Known Speakers
- Pick a recording you would like to tag speakers in.
- Files - "My Awesome Recording"
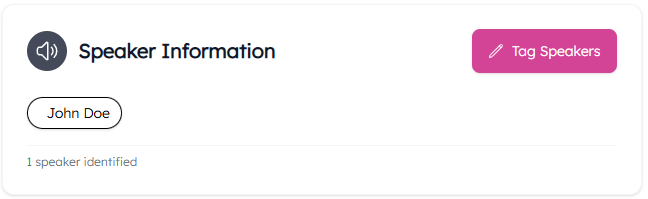
- Hit "Tag Speakers" from the Speaker Information card.
- The Assign Speakers Page breaks the recording's transcript up by speaker.
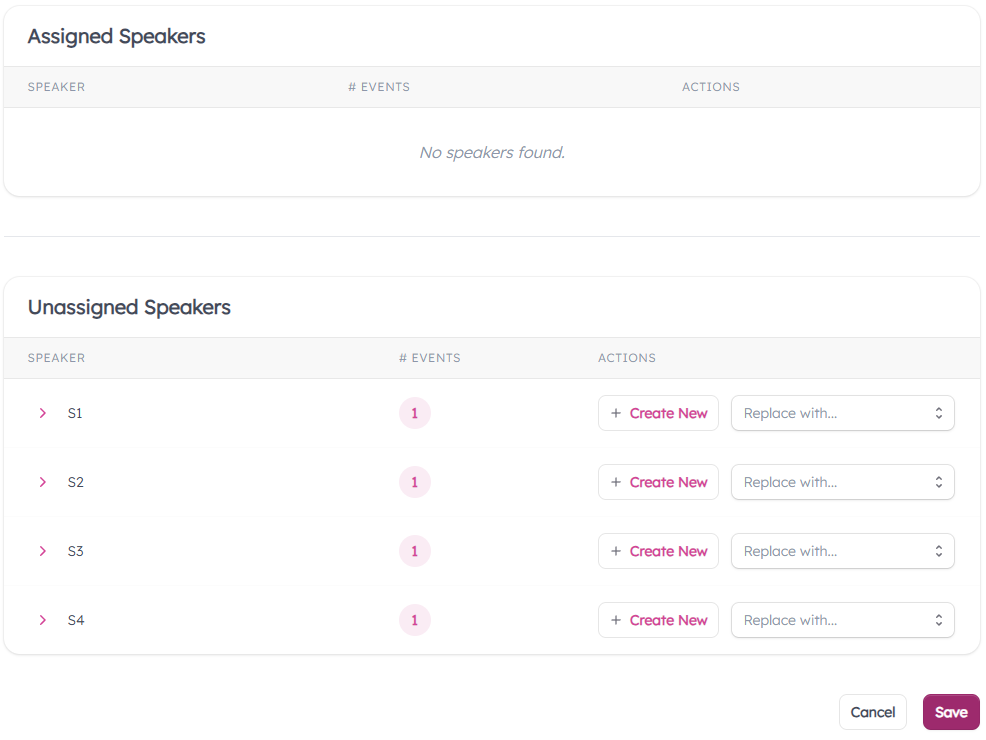
- Expand one of the rows under "Unassigned Speakers" to view a transcript of events the speaker participated in.
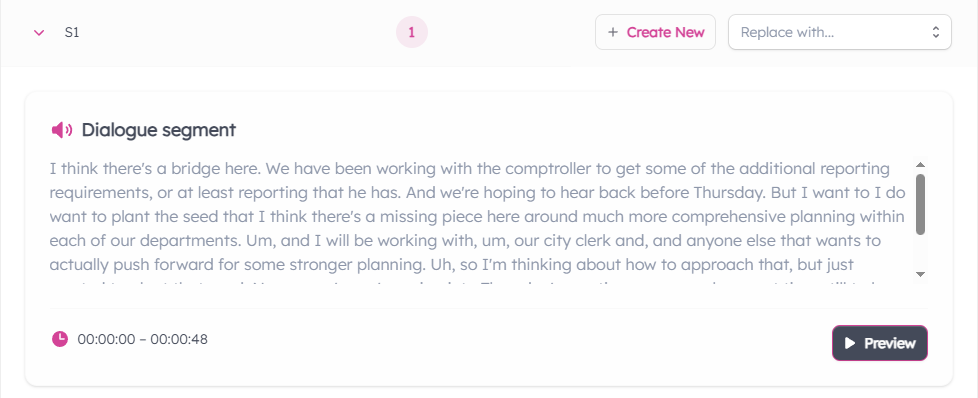
- You can hit "Preview" to view the event during with video playback.
- Hit "Create New" on one of the rows to enter the speaker's information.
- "Name" is only used internally.
- "Label" is what is displayed during live captioning and gets saved to the transcript files.
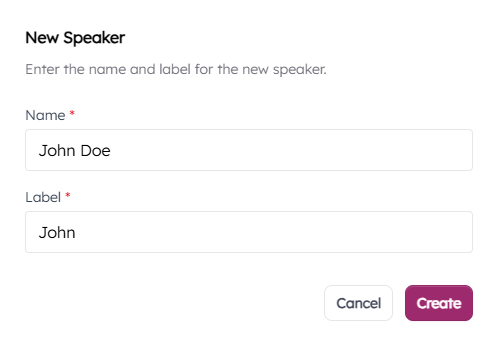
- Hit "Create". The speaker event is moved to "Assigned Speakers". Any previously assigned speakers will also be listed in this section.
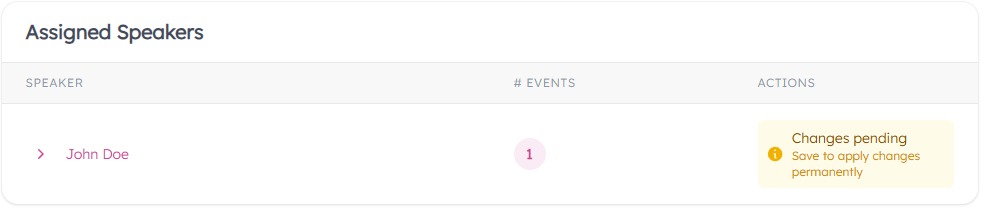
- You may also choose "Replace" for any Assigned or Unassigned speaker event.
- Select a previously created speaker from the dropdown.
- You may assign the same speaker to multiple dialogue events across multiple recordings.
- Hit "Save". Any changes made will be applied. New speakers will be queued for audio processing and replaced speakers will be overwritten.
Editing Speaker Information
- Navigate to Settings - Speakers.
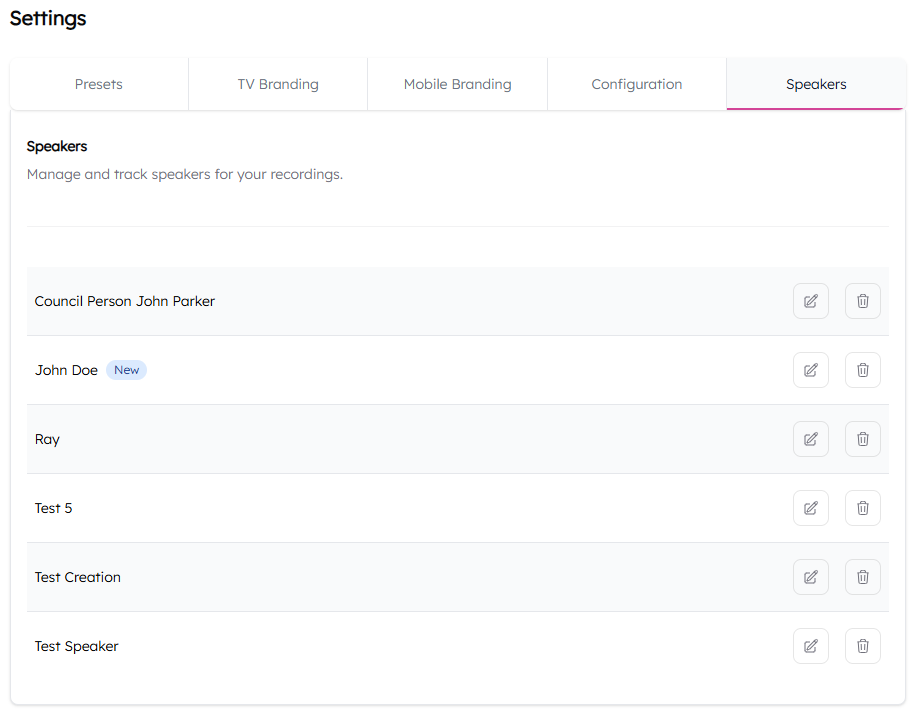
- Hit the pencil icon to edit a speaker's information.
- Hit the trash icon to remove a speaker from the system.
- The status of each speaker is displayed next to their name.

Assigning Speakers to a Preset
- Navigate to Settings - Presets - "My Preset" - Speakers
- Use the checkboxes to assign and un-assign speakers from a Preset.
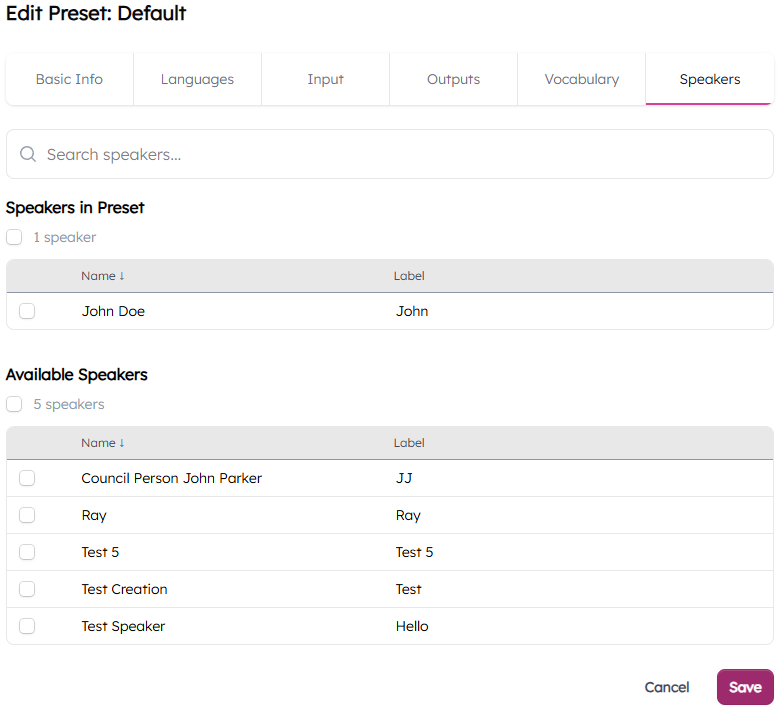
- Once a speaker is assigned to a Preset, their label will be displayed when speaking during a live meeting.
Under the Hood
It is important to mention that no audio data is stored within the speaker identification pipeline. Once you tag a speaker in a clip, the audio data is sent to Speechmatics for processing. They return to us a hashed key value (or multiple) that represents the speaker being processed. We then send this key, and any others in the Preset, back to them during live transcription. Speechmatics compares the speaker keys it generates with the keys we send up. When a match is found, the speaker's generic label (S1, S2, etc.) is swapped for the name we tagged.
